- 品牌
- 智会云
- 型号
- ICCT-200YY
- 产地
- 广州
- 可售卖地
- 全国
- 是否定制
- 是
为满足不同用户需求,语音转写产品开发了丰富的个性化功能,掌握使用技巧可进一步提升体验。自定义词典功能支持添加行业术语、人名、地名,例如法律从业者可导入 “诉讼时效”“代位权” 等专业词汇,提升领域内转写准确率;语速调节功能可适配不同说话人语速,针对快速发言场景,开启 “慢语速优化” 模式,减少漏字错字;多格式导出支持关联时间戳,点击文字即可回溯对应语音片段,便于核对修正。使用时建议:在安静环境下录制语音,减少背景噪音干扰;开始使用前完成个性化语音训练(部分产品支持),让模型适配个人口音;转写后重点核对数字、专业术语,确保关键信息准确无误。利用语音转写功能,教育工作者可以将教学讲解语音转写成文字辅助教学。自动记录语音转写好用吗
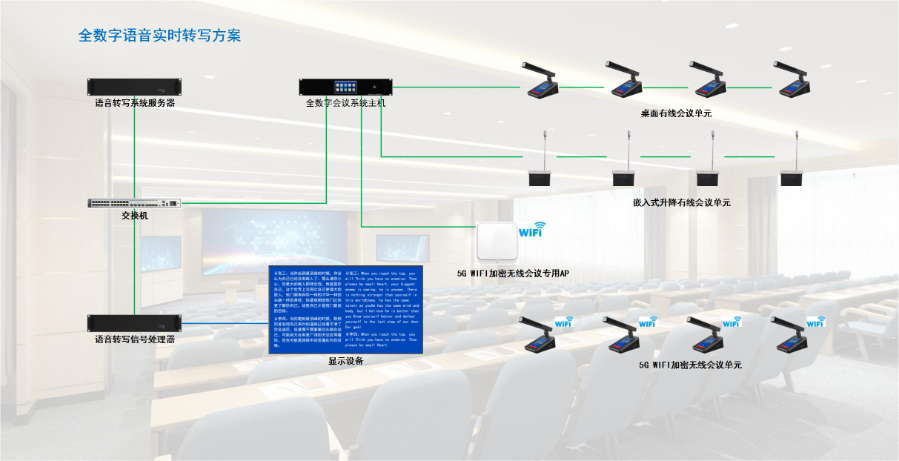
尽管智能语音转写取得了明显进步,但仍然存在一些技术局限亟待解决.一方面,在复杂的环境中,如存在大量背景噪音的情况下,语音转写的准确率会受到一定影响.这是因为背景噪音会干扰语音信号的提取和分析,使得系统难以准确识别语音内容.另一方面,对于一些非常专业、生僻的词汇和领域特定术语,语音转写系统可能无法准确识别.针对这些问题,研究人员正在不断探索新的技术和方法.例如,研发更先进的降噪算法来提高在复杂环境中的识别能力,以及加强特定领域的语料库建设,使系统能够更好地理解和处理专业词汇.未来,智能语音转写技术将朝着更加精细、高效、智能化的方向发展,为用户提供更好的服务.无纸化语音转写作用学术讲座转写自动标注参考文献格式,辅助科研人员整理资料撰写论文。

语音转写产品较重心的优点在于较好的效率提升,彻底改变传统人工记录的低效模式。传统人工记录会议、采访或课程内容时,不需全程专注避免遗漏,后续整理还需逐句核对、补全信息,1 小时的语音内容往往需要 3-4 小时才能整理成完整文字;而语音转写产品可实现 “语音结束即出文字”,1 小时语音较快 5 分钟内完成转写,且支持实时转写模式,会议或课程进行中就能同步生成文字记录,会后无需额外整理,直接导出可用文档。这种效率优势让使用者从繁琐的记录工作中解放,将更多时间投入到内容分析、思考决策等重心事务中,尤其适合高频处理语音信息的职场人、教育工作者与创作者。
语音转写产品具备持续迭代优化的能力,能根据用户反馈、技术发展与场景变化动态升级功能,始终保持产品竞争力,这是其长期满足用户需求的重要优点。在迭代机制上,建立 “用户反馈 - 需求分析 - 技术研发 - 测试上线” 的闭环体系,通过产品内反馈入口、用户调研、社群的交流等渠道收集需求,优先解决高频痛点,例如针对用户反映的 “方言转写准确率低” 问题,快速扩充方言语料库并优化模型;在技术升级上,紧跟 AI 领域发展趋势,将较新的语音识别算法、自然语言处理技术融入产品,如引入 Transformer 架构提升复杂场景识别准确率,采用大模型技术增强智能辅助能力;在场景适配升级上,针对新兴场景快速开发功能,例如直播行业兴起后,迅速推出 “直播实时字幕” 功能,满足主播与观众的跨平台需求,让产品始终贴合市场变化,为用户提供更不错的体验。企业定制版语音转写可添加企业LOGO,设计专属界面,强化品牌辨识度。

在当今社会,司法公开是法治建设的重要内容.公众对司法审判的知情权和监督权越来越受到重视.智能语音转写应用为司法公开提供了有力的技术支持.庭审记录的文字版可以通过法院官方网站、司法公开平台等渠道向公众公开,让公众能够及时了解案件的审理过程.这使得司法审判不再是一个神秘的过程,公众可以清楚地看到案件的证据展示、当事人的陈述和辩论等环节.这增强了司法的透明度和公信力,使公众对司法审判有更直观的认识.同时,对于当事人和社会监督者来说,他们可以通过查阅庭审记录来监督司法审判的公正性,促进司法权力的正确行使,让司法更加公正、透明.语音转写软件可对语音中的停顿和重音进行分析,使转写更符合语义逻辑。南京AI智能语音转写字幕
视障用户使用语音转写时,屏幕阅读器同步播报内容,辅助完成操作。自动记录语音转写好用吗
语音转写产品具备极强的设备适配性,支持多终端无缝衔接使用,满足用户在不同场景下的设备切换需求,这一优点大幅提升了使用灵活性。在设备覆盖上,可完美适配电脑(Windows/Mac)、手机(iOS/Android)、平板、智能录音笔等多种设备,用户在电脑端开启会议转写后,外出途中可通过手机端实时查看进度,回到办公室再用平板端编辑文档,数据实时同步不丢失;在设备联动上,支持与智能硬件深度协作,例如连接智能麦克风后,可增强语音采集效果,减少环境噪音干扰,连接打印机可直接导出转写文档并打印,无需额外传输文件;针对特殊设备,如工业级录音设备、车载系统,也能通过定制化接口实现适配,确保在户外作业、车载办公等场景下正常使用,真正实现 “随时随地,想用就用”。自动记录语音转写好用吗

语音转写产品主要有三种付费模式,用户可根据需求选择高性价比方案。第一种是试用模式,提供基础转写功能(如单次转写时长不超过 30 分钟、支持 TXT 格式导出),适合偶尔使用的用户;第二种是会员订阅模式,分为月卡、季卡、年卡,年卡性价比较高,会员可享受无时长限制转写、多格式导出、自定义词典扩容等特权,适合高频使用的职场人、学生;第三种是企业定制付费模式,按企业人数、使用场景定价,提供专属客服、数据本地化部署、系统集成服务,适合大型企业或机构。选择策略上,偶尔整理录音选版,日常办公或学习选年卡会员,企业级应用则定制专属方案,部分平台还会推出节日优惠(如开学季、年终促销),可趁机入手长期套餐。利用语...
- 上海多角色语音转写售后 2026-01-21
- 南京实时语音转写报价 2026-01-21
- 长沙自动翻译语音转写故障排除 2026-01-21
- 上海角色分离语音转写字幕 2026-01-21
- 广州自动记录语音转写 2026-01-21
- 多语言识别语音转写好用吗 2026-01-21
- 广州语音转写同时转写 2026-01-21
- 全数字语音转写软件系统 2026-01-20
- 上海智能语音转写字幕 2026-01-20
- 长沙多语言识别语音转写报价 2026-01-20


- 北京自动记录语音转写有什么功能 2026-01-20
- 上海自动记录语音转写云平台 2026-01-19
- 南京多角色语音转写云平台 2026-01-19
- 北京智能翻译语音转写故障排除 2026-01-19
- 南京文字识别语音转写软件 2026-01-19
- 上海全数字语音转写价格 2026-01-19



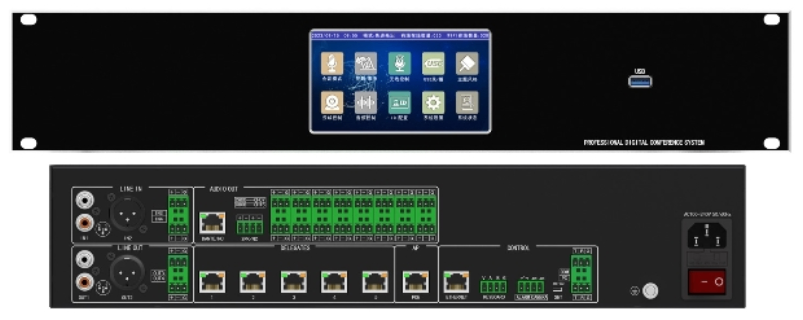
- 智能会议预约云平台 01-21
- 长沙智能会议预约 01-21
- 上海角色分离语音转写字幕 01-21
- 广州自动记录语音转写 01-21
- 长沙智慧办公会议预约哪家好 01-21
- 智能平台会议预约好用吗 01-21
- 多语言识别语音转写好用吗 01-21
- 广州语音转写同时转写 01-21
- 全数字语音转写软件系统 01-20
- 上海智能语音转写字幕 01-20