- 品牌
- 智会云
- 型号
- ICCT-200YY
- 产地
- 广州
- 可售卖地
- 全国
- 是否定制
- 是
在学习和教育领域,智能语音转写应用正发挥着越来越重要的作用,为师生们带来了诸多便利和创新的学习体验.对于学生来说,它是学习过程中的得力助手.以学习外语为例,听力是外语学习的重要板块之一,但很多时候学生很难通过单纯地听听力材料来完全理解其中的词汇和语法知识.而借助语音转写功能,学生可以将听力材料转化为文字,对照着详细的文字内容进行听力练习,这样不可以更准确地捕捉每一个单词和句子的含义,还能加深对重点词汇和语法结构的理解和记忆.对于教育工作者而言,智能语音转写应用也极大地减轻了他们的工作负担.教师在备课过程中,需要对大量的教学资料进行整理和分析,语音转写可以帮助他们快速地将音频资料转化为文字,方便进行备课和教案编写.在课堂教学中,教师也可以通过语音转写记录下重要的知识点和学生的讨论内容,为后续的教学评估和反馈提供有力依据,从而不断提升教学质量.语音转写的词汇替换功能可批量修正相同错误,减少逐字核对的时间成本。长沙声音转文字语音转写故障排除

无纸化语音转写是现代科技的一项不错成果.在信息炸的现在,传统的纸质记录方式面临着诸多挑战,如空间占用、查找不便等.而语音转写技术让一切变得更为高效.它能够将口述内容快速、准确地转化为电子文字.无论是在会议场景中,各种观点和决策迅速被语音捕捉并转写,还是在个人学习记录方面,如语言学习的口语练习转化成文字复习资料,都极大地提高了效率.而且语音转写系统不断学习优化,对于不同口音、语速都有了更强的适应性,减少了转换过程中的错误,为使用者提供了可靠、便捷的无纸化记录手段.全数字语音转写软件系统语音转写技术能适应不同的语速,无论是快语速还是慢语速都能准确转写。

为满足残障用户需求,语音转写产品推出无障碍服务适配功能。针对视障用户,产品支持与屏幕阅读器深度兼容,转写过程中的操作提示、文字内容可通过语音播报同步输出,方便视障用户完成转写启停、文档保存等操作;针对听障用户,除实时语音转文字外,还支持 “文字转语音” 反向功能,听障用户输入文字后,系统可转化为清晰语音与他人沟通,同时转写内容可生成超大字体版本,适配听障用户阅读习惯;针对肢体残障用户,产品支持语音控制功能,用户通过 “开启转写”“导出文档” 等语音指令即可操作,无需手动点击,同时适配外接辅助设备(如定制键盘、摇杆),降低操作难度。这些无障碍适配让残障用户能便捷使用语音转写服务,享受科技带来的便利。
语音转写产品具备全场景适配优势,能灵活满足不同行业、不同人群的多样化使用需求,打破场景局限。在职场领域,适配会议记录、客户访谈、项目汇报等场景,支持多 speaker 分离、重点标注功能;在教育领域,适配课堂教学、学术讲座、学生笔记场景,提供知识点提取、双语对照功能;在生活领域,适配家庭录音整理、自媒体口播脚本创作、老人语音记事场景,支持轻量化操作与离线使用;在专业领域,还能深度适配医疗病历记录、法律庭审记录、物流调度沟通等垂直场景,提供符合行业规范的定制化功能。无论是室内安静环境还是户外嘈杂环境,无论是短时长语音还是数小时长音频,产品都能稳定发挥作用,真正实现 “全场景可用”。语音转写工具支持对不同风格演讲的语音进行转写,满足多样化需求。

语音转写产品强化实时字幕生成能力,适配多场景观看与传播需求。在线上直播场景,支持 “语音实时转写 + 字幕同步叠加”,主播语音可瞬间转化为字幕并显示在直播画面中,支持中英双语字幕切换,适配听力障碍观众与跨境观看人群,同时字幕可自定义字体、颜色与位置,贴合直播风格;在视频会议场景,实时字幕可按发言人身份自动区分颜色,如主持人字幕用蓝色、参会人字幕用黑色,便于快速识别发言主体,提升会议信息接收效率;针对短视频创作,产品可将视频语音转写为字幕并自动匹配时间轴,支持字幕批量编辑与风格统一,减少创作者手动添加字幕的工作量,同时支持多平台字幕格式导出(如抖音 srt、B 站 ass),适配不同短视频平台需求。语音转写技术可识别带有背景音乐的语音,尽量减少音乐对转写的干扰。全数字语音转写软件系统
语音转写系统能对语音中的专业词汇进行智能联想和转写。长沙声音转文字语音转写故障排除
为提升转写准确性,语音转写产品设计了完善的错误修正机制与持续优化逻辑。错误修正机制包含实时修正与批量修正,实时转写时,用户发现错误可直接点击文字进行修改,系统记录修正内容并反馈至模型;批量修正则支持用户上传修正后的文档,模型通过对比原转写内容与修正内容,学习错误类型特征,减少同类错误再次发生。优化逻辑上,产品后台构建错误分析系统,定期统计转写错误类型,如词汇误识、语法错误、漏字等,针对高频错误优化模型算法与语料库;同时,结合用户反馈数据,优先解决用户关注的重点场景错误问题,通过 “用户反馈 - 数据统计 - 模型优化 - 效果验证” 的闭环,持续提升产品转写准确率与用户体验。长沙声音转文字语音转写故障排除

语音转写软件的精细性使其在众多领域备受青睐,这得益于先进的技术支撑.其精细识别依赖复杂的声学和语言模型分析.声学模型能细致分析和建模语音的声学特征,无论语音的音色、语调、音量如何变化,都能精细捕捉细节.语言模型基于大规模语料库训练,能理解不同语境下的语义信息,准确将语音转化为文字.在实际应用中,对于各种口音,如不同地区方言或特定文化背景下的口音,软件都能较好识别关键信息.面对连读、弱读等复杂语音现象,也能通过智能算法处理,还原语义.比如在快速对话场景下,软件能通过音素分析准确识别连读内容.其高准确的识别结果减少了人工校对工作量,让用户能更专注于信息处理和分析.语音转写技术能适应不同的语音编码格...
- 长沙智能语音转写云平台 2026-01-03
- 法院语音转写价格 2026-01-02
- 南京国产化语音转写售后 2026-01-02
- 长沙声音转文字语音转写故障排除 2026-01-02
- 上海多语种识别语音转写报价 2026-01-01
- 广州实时语音转写软件 2026-01-01
- 南京智能语音转写好用吗 2026-01-01
- 语音转写好用吗 2026-01-01
- 长沙多语种识别语音转写怎么样 2026-01-01
- 北京语音转写字幕 2026-01-01



- 北京无纸化语音转写软件系统 2025-12-31
- 南京多语种识别语音转写售后 2025-12-31
- 语音转写售后维护 2025-12-31
- 广州多语言识别语音转写云平台 2025-12-31
- 多角色语音转写报价 2025-12-31
- 长沙全数字语音转写字幕 2025-12-31

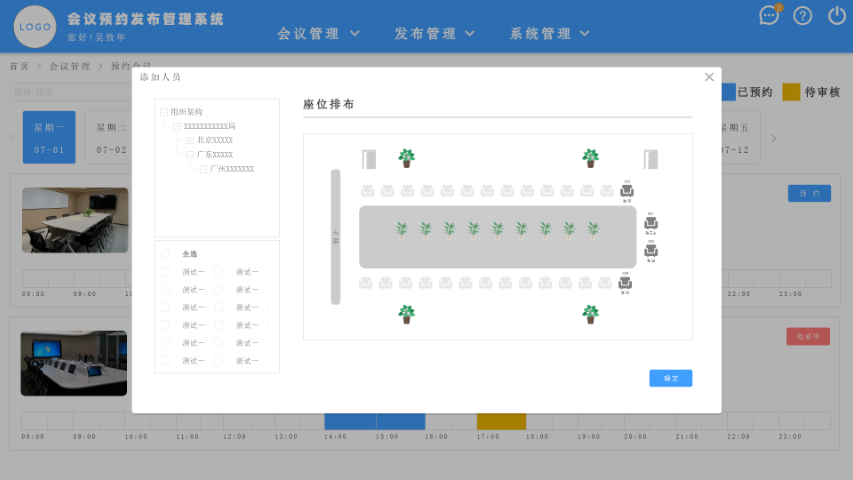
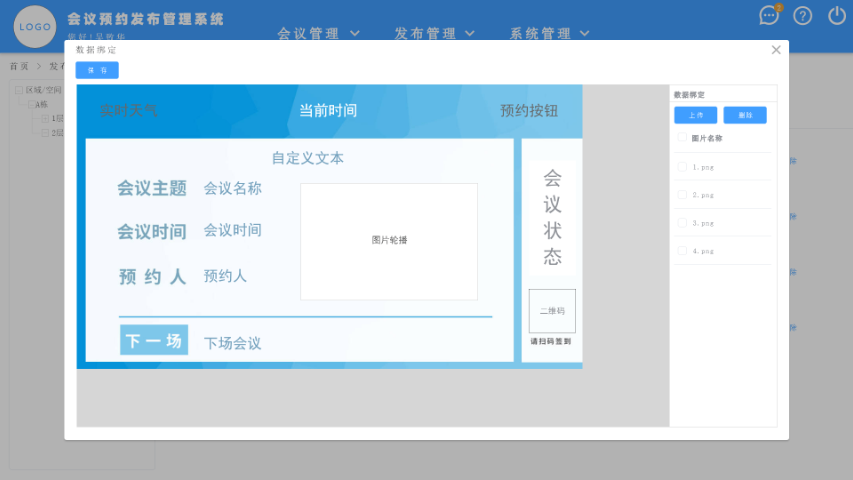
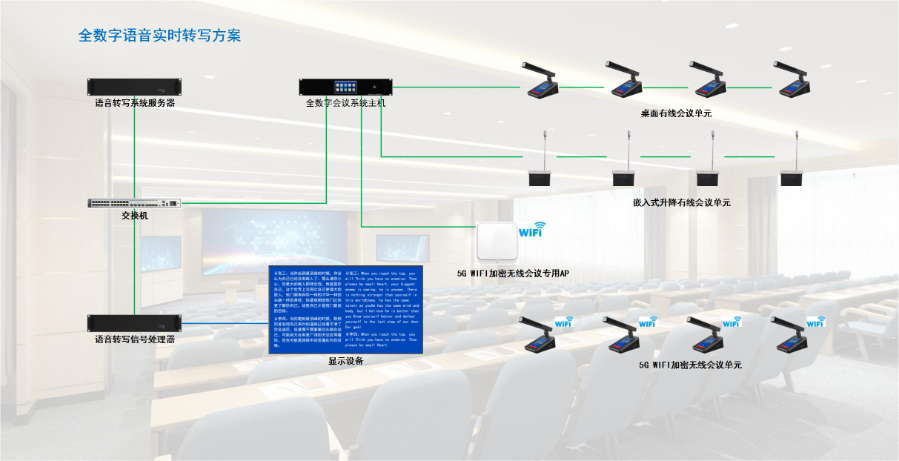
- 上海智慧办公会议预约售后 01-03
- 长沙智能语音转写云平台 01-03
- 上海智能平台会议预约哪家好 01-03
- 法院语音转写价格 01-02
- 长沙会议预约售后维护 01-02
- 上海智能会议预约管理系统 01-02
- 北京英文版会议预约软件系统 01-02
- 广州会议室管理会议预约 01-02
- 长沙会议预约管理系统 01-02
- 南京国产化语音转写售后 01-02